人工智能最早的探索也许可以追溯到莱布尼茨,他试图制造能够进行自动符号计算的机器,但现代意义上人工智能这个术语诞生于1956年的达特茅斯会议。
关于人工智能有很多的定义,它本身就是很多学科的交叉融合,不同的人关注它的不同方面,因此很难给出一个大家都认可的一个定义。我们下面通过时间的脉络来了解AI的反正过程。
黄金时期(1956-1974)
这是人工智能的一个黄金时期,大量的资金用于支持这个学科的研究和发展。这一时期有影响力的研究包括通用问题求解器(General Problem Solver),以及最早的聊天机器人ELIZA。很多人都以为与其聊天的ELIZA是一个真人,但它只是简单的基于匹配模板的方式来生成回复(我们现在很多市面上的聊天机器人其实也使用了类似的技术)。当时人们非常乐观,比如H. A. Simon在1958年断言不出10年计算机将在下(国际)象棋上击败人类。他在1965年甚至说“二十年后计算机将可以做所有人类能做的事情”。
第一次寒冬(1974-1980)
到了这一时期,之前的断言并没有兑现,因此各种批评之声涌现出来,国家(美国)也不再投入更多经费,人工智能进入第一次寒冬。这个时期也是联结主义(connectionism)的黑暗时期。1958年Frank Rosenblatt提出了感知机(Perception),这可以认为是最早的神经网络的研究。但是在之后的10年联结主义没有太多的研究和进展。
兴盛期(1980-1989)
这一时期的兴盛得益于专家系统的流行。联结主义的神经网络也有所发展,包括1982年John Hopfield提出了Hopfield网络,以及同时期发现的反向传播算法,但主流的方法还是基于符号主义的专家系统。
第二次寒冬(1989-1993)
之前成功的专家系统由于成本太高以及其它的原因,商业上很难获得成功,人工智能再次进入寒冬期。
发展期(1993-2006)
这一期间人工智能的主流是机器学习。统计学习理论的发展和SVM这些工具的流行,使得机器学习进入稳步发展的时期。
爆发期(2006-现在)
这一次人工智能的发展主要是由深度学习,也就是深度神经网络带动的。上世纪八九十年度神经网络虽然通过非线性激活函数解决了理论上的异或问题,而反向传播算法也使得训练浅层的神经网络变得可能。不过,由于计算资源和技巧的限制,当时无法训练更深层的网络,实际的效果并不比传统的“浅度”的机器学习方法好,因此并没有太多人关注这个方向。
直到2006年,Hinton提出了Deep Belief Nets (DBN),通过pretraining的方法使得训练更深的神经网络变得可能。2009年Hinton和DengLi在语音识别系统中首次使用了深度神经网络(DNN)来训练声学模型,最终系统的词错误率(Word Error Rate/WER)有了极大的降低。
让深度学习在学术界名声大噪的是2012年的ILSVRC评测。在这之前,最好的top5分类错误率在25%以上,而2012年AlexNet首次在比赛中使用了深层的卷积网络,取得了16%的错误率。之后每年都有新的好成绩出现,2014年是GoogLeNet和VGG,而2015年是ResNet残差网络,目前最好系统的top5分类错误率在5%以下了。真正让更多人(尤其是中国人)了解深度学习进展的是2016年Google DeepMind开发的AlphaGo以4比1的成绩战胜了人类世界冠军李世石。因此人工智能进入了又一次的兴盛期,各路资本竞相投入,甚至国家层面的人工智能发展计划也相继出台。
2006年到现在分领域的主要进展
下面我们来回顾一下从2006年开始深度学习在计算机视觉、听觉、自然语言处理和强化学习等领域的主要进展,根据它的发展过程来分析未来可能的发展方向。因为作者水平和兴趣点的局限,这里只是列举作者了解的一些文章,所以肯定会遗漏一些重要的工作。
无监督预训练
虽然”现代”深度学习的很多模型,比如DNN、CNN和RNN(LSTM)很早就提出来了,但在2006年之前,大家没有办法训练很多层的神经网络,因此在效果上深度学习和传统的机器学习并没有显著的差别。
2006年,Hinton等人在论文《A fast learning algorithm for deep belief nets》里提出了通过贪心的、无监督的Deep Belief Nets(DBN)逐层Pretraining的方法和最终有监督fine-tuning的方法首次实现了训练多层(五层)的神经网络。此后的研究热点就是怎么使用各种技术训练深度的神经网络,这个过程大致持续到2010年。主要的想法是使用各种无监督的Pretraining的方法,除了DBN,Restricted Boltzmann Machines(RBM), Deep Boltzmann Machines(DBM)还有Denoising Autoencoders等模型也在这一期间提出。
代表文章包括Hinton等人的《Reducing the dimensionality of data with neural networks》发表在Nature上)、Bengio等人在NIPS 2007上发表的《Greedy layer-wise training of deep networks》,Lee等人发表在ICML 2009上的《Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations》,Vincent等人2010年发表的《Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion》。
那个时候要训练较深的神经网络是非常tricky的事情,因此也有类似Glorot等人的《Understanding the difficulty of training deep feedforward neural networks》,大家在使用深度学习工具时可能会遇到Xavier初始化方法,这个方法的作者正是Xavier Glorot。那个时候能把超参数选好从而能够训练好的模型是一种”黑科技”,我记得还有一本厚厚的书《Neural Networks: Tricks of the Trade》,专门介绍各种tricks。
深度卷积神经网络
深度学习受到大家的关注很大一个原因就是Alex等人实现的AlexNet在LSVRC-2012 ImageNet这个比赛中取得了非常好的成绩。此后,卷积神经网络及其变种被广泛应用于各种图像相关任务。从2012年开始一直到2016年,每年的LSVRC比赛都会产生更深的模型和更好的效果。
Alex Krizhevsky在2012年的论文《ImageNet classification with deep convolutional neural networks》开启了这段”深度”竞争之旅。
2014年的冠军是GoogleNet,来自论文《Going deeper with convolutions》,它提出了Inception的结构,通过这种结构可以训练22层的深度神经网络。它同年的亚军是VGGNet,它在模型结构上并没有太多变换,只是通过一些技巧让卷积网络变得更深(18层)。
2015年的冠军是ResNet,来自何恺明等人的论文《Deep residual learning for image recognition》,通过引入残差结构,他们可以训练152层的网络,2016年的文章《Identity Mappings in Deep Residual Networks》对残差网络做了一些理论分析和进一步的改进。
2016年Google的Szegedy等人在论文《Inception-v4, inception-resnet and the impact of residual connections on learning》里提出了融合残差连接和Incpetion结构的网络结构,进一步提升了识别效果。
下图是这些模型在LSVRC比赛上的效果,我们可以看到随着网络的加深,分类的top-5错误率在逐渐下降。
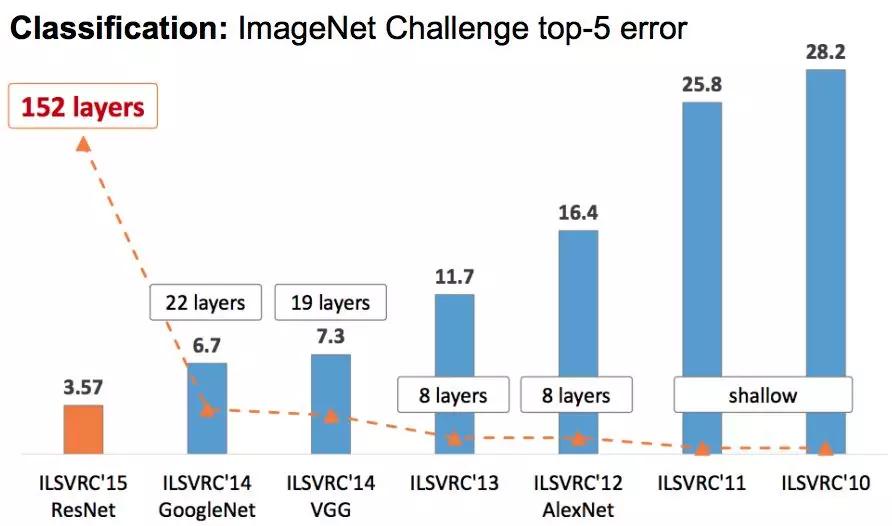
图:LSVRC比赛
目标检测和实例分割
前面的模型主要考虑的是图片分类任务,目标检测和实例分割也是计算机视觉非常常见的任务。把深度卷积神经网络用到这两个任务上是非常自然的事情,但是这个任务除了需要知道图片里有什么物体,还需要准确的定位这些物体。为了把卷积神经网络用于这类任务,需要做很多改进工作。
当然把CNN用于目标检测非常自然,最简单的就是先对目标使用传统的方法进行定位,但是定位效果不好。Girshick等人在2014年在论文《Rich feature hierarchies for accurate object detection and semantic segmentation》提出了R-CNN模型,使用Region Proposal来产生大量的候选区域,最后用CNN来判断是否是目标,但因为需要对所有的候选进行分类判断,因此它的速度非常慢。
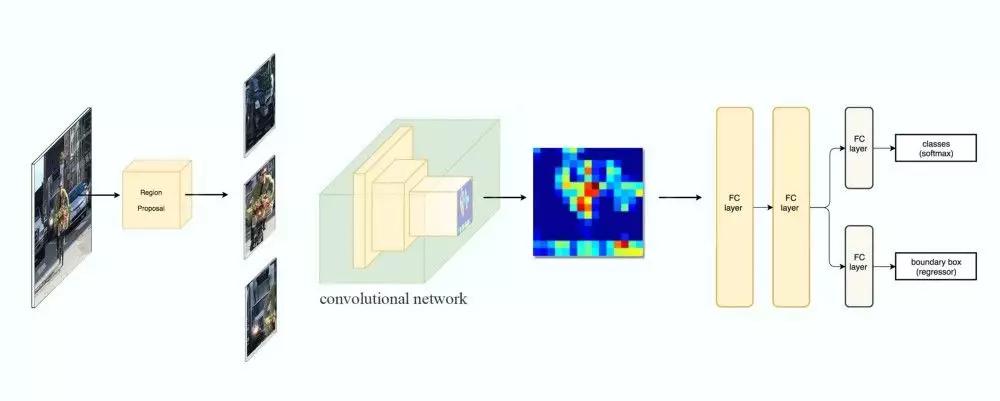
图:R-CNN
2015年,Girshick等人提出了Fast R-CNN,它通过RoI Pooling层通过一次计算同时计算所有候选区域的特征,从而可以实现快速计算。但是Regional Proposal本身就很慢,Ren等人在同年的论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》提出了Faster R-CNN,通过使用Region Proposal Networks(RPN)这个网络来替代原来的Region Proposal算法,从而实现实时目标检测算法。为了解决目标物体在不同图像中不同尺寸(scale)的问题,Lin等人在论文《Feature Pyramid Networks for Object Detection》里提出了Feature Pyramid Networks(FPN)。
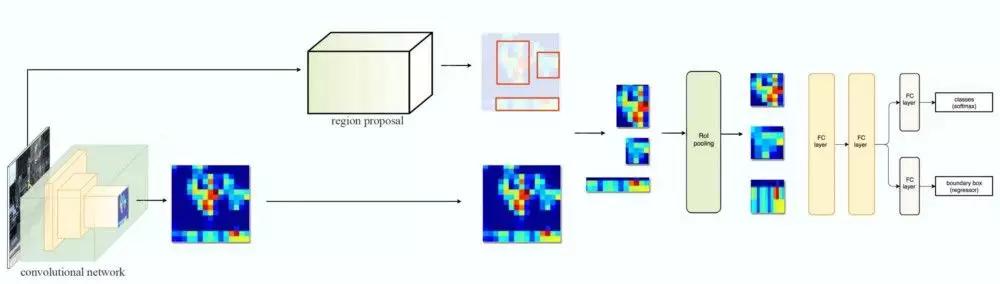
图:Fast R-CNN
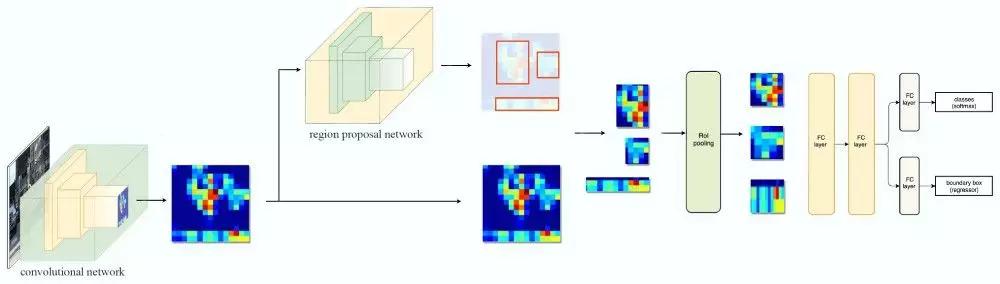
图:Faster R-CNN
因为R-CNN在目标检测任务上很好的效果,把Faster R-CNN用于实例分割是很自然的想法。但是RoI Pooling在用于实例分割时会有比较大的偏差,原因在于Region Proposal和RoI Pooling都存在量化的舍入误差。因此何恺明等人在2017年提出了Mask R-CNN模型。
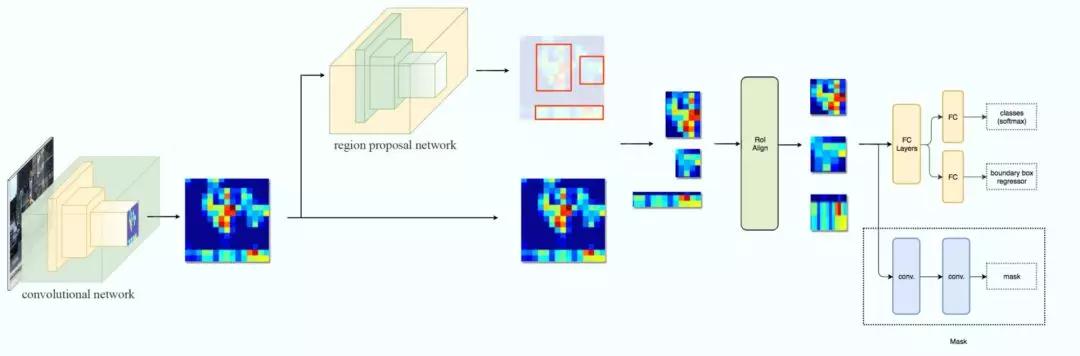
图:Mask R-CNN
从这一系列文章我们可以看到深度学习应用于一个更复杂场景的过程:首先是在一个复杂的过程中部分使用深度神经网络,最后把所有的过程End-to-End的用神经网络来实现。
此外,Redmon等人《You only look once: Unified, real-time object detection》提出了YOLO模型(包括后续的YOLOv2和YOLOv3等),Liu等人也提出的SSD: Single Shot MultiBox Detector模型,这些模型的目的是为了保持准确率不下降的条件下怎么加快检测速度。
生成模型
如果要说最近在计算机视觉哪个方向最火,生成模型绝对是其中之一。要识别一个物体不容易,但是要生成一个物体更难(三岁小孩就能识别猫,但是能画好一只猫的三岁小孩并不多)。而让生成模型火起来的就是Goodfellow在2014年提出的Generative Adversarial Nets(简称GAN)。
因为这个领域比较新,而且研究的”范围”很广,也没有图像分类这样的标准任务和ImageNet这样的标准数据集,很多时候评测的方法非常主观。很多文章都是找到某一个应用点,然后生成(也可能是精心挑选)了一些很酷的图片或者视频,”有图有真相”,大家一看图片很酷,内容又看不懂,因此不明觉厉。要说解决了什么实际问题,也很难说。但是不管怎么说,这个方向是很吸引眼球的,比如DeepFake这样的应用一下就能引起大家的兴趣和讨论。我对这个方向了解不多,下面只列举一些应用。
style-transfer
最早的《A Neural Algorithm of Artistic Style》发表于2015年,这还是在GAN提出之前,不过我还是把它放到生成模型这里了。它当年可是火过一阵,还因此产生了一个爆款的App叫Prisma。如下图所示,给定一幅风景照片和一幅画(比如c是梵高的画),使用这项技术可以在风景照片里加入梵高的风格。

图:Neural Style Transfer
朱俊彦等人在《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》提出的CycleGAN是一个比较有趣其的模型,它不需要Paired的数据。所谓Paired数据,就是需要一张普通马的照片,还需要一张斑马的照片,而且要求它们内容是完全匹配的。要获得配对的数据是非常困难的,我们拍摄的时候不可能找到外形和姿势完全相同的斑马和普通马,包括相同的背景。另外给定一张梵高的作品,我们怎么找到与之配对的照片?或者反过来,给定一张风景照片,去哪找和它内容相同的艺术作品?
本文介绍的Cycle GAN不要求有配对的训练数据,而只需要两个不同Domain的未标注数据集就行了。比如要把普通马变成斑马,我们只需要准备很多普通马的照片和很多斑马的照片,然后把所有斑马的照片放在一起,把所有的普通马照片放到一起就行了,这显然很容易。风景画变梵高风格也很容易——我们找到很多风景画的照片,然后尽可能多的找到梵高的画作就可以了。它的效果如下图所示。

图:CycleGAN
text-to-image
text-to-image是根据文字描述来生成相应的图片,这和Image Captioning正好相反。Zhang等人2016年的《StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》是这个方向较早的一篇文章,其效果如下图最后一行所示。

图:StackGAN和其它模型的对比
super-resolution
super-resolution是根据一幅低分辨率的图片生成对应高分辨率的图片,和传统的插值方法相比,生成模型因为从大量的图片里学习到了其分布,因此它”猜测”出来的内容比插值效果要好很多。《Enhanced Super-Resolution Generative Adversarial Networks》是2018年的一篇文章,它的效果如下图中间所示。
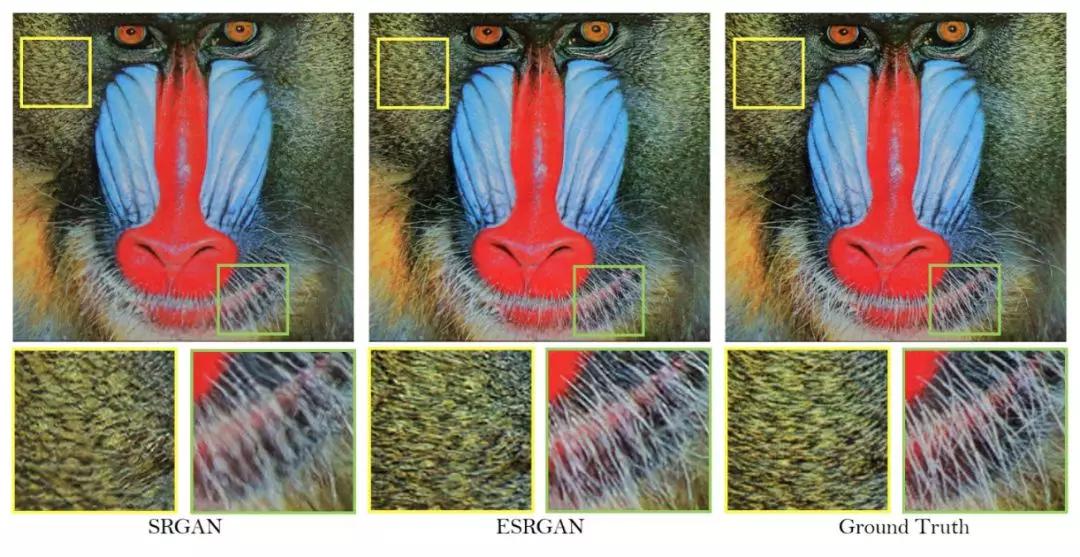
图:ESRGAN效果
image inpainting
image inpainting是遮挡掉图片的一部分,比如打了马赛克,然后用生成模型来”修补”这部分内容。下图是Generative Image Inpainting with Contextual Attention的效果。

图:DeepFill系统的效果
《EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning》这篇文章借鉴人类绘画时先画轮廓(线)后上色的过程,通过把inpainting分成edge generator和image completion network两个步骤,如下面是它的效果。
图:EdgeConnect的效果
最新热点:自动优化网络结构和半监督学习
最近有两个方向我觉得值得关注:一个是自动优化网络结构;另一个是半监督的学习。
自动网络优化最新的文章是Google研究院的《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》,它希望找到一个神经网络扩展方法可以同时提高网络的准确率和效率(减少参数)。要实现这点,一个很关键的步骤便是如何平衡宽度、深度和分辨率这三个维度。